Tweaking voice interface + (optional) auto-training on your voice


The more I use it, the more I think that a "talking and listening" canvas is 100% the way forward with this kind of interface. It just "feels" so much more natural. Choosing what blocks can speak to you with a "speak" block - and you choosing which blocks to talk TO simply by hovering over them and... well, talking...
This got me thinking... We are already transcribing incoming audio, why not use those audio snippets for a dual-purpose to (optionally!) send those clips to train a special model on your voice.
Note: These ElevenLabs custom trained voices are private to your account/API key by default.
It actually works pretty well...
So, I decided - it will be in next weeks Docker image along with all the other voice additions and changes (kits / sub-grouping, etc).
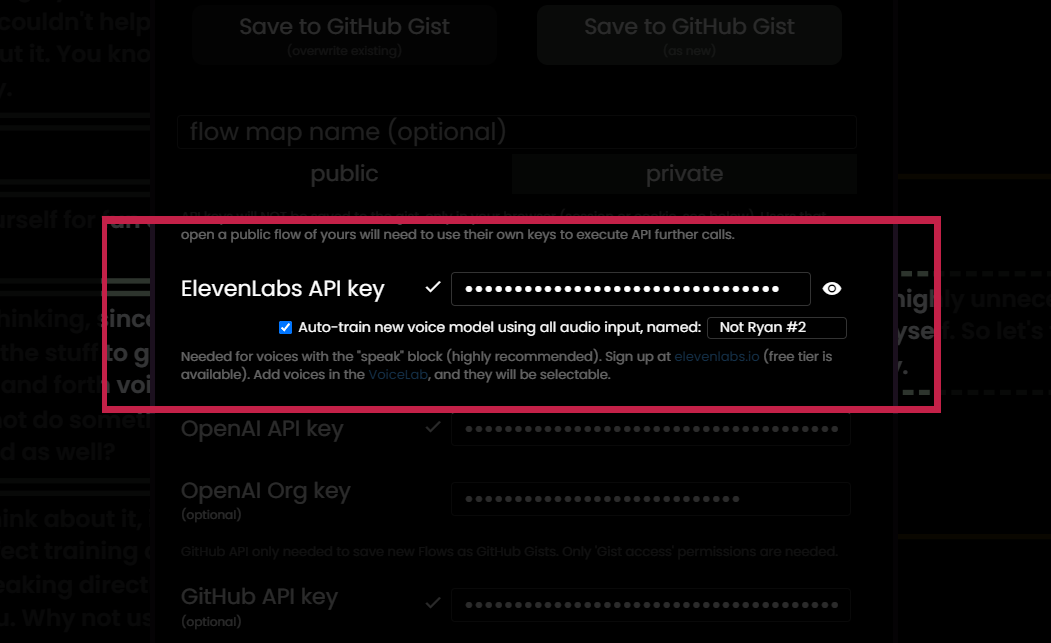
I don't know what kind of psycho would want an AI chat bot assistant that was voiced by THEMSELVES - but hey, if that's you, go for it. :)
Oh yeah, and I made the "speak" blocks announce themselves in a random voice when they are added to the canvas - it's goofy, but I'd be lying if said that I didn't laugh almost every time it happens...